From research to compounding wins.
Every plan we run follows the same framework. Research first. Hypothesis next. Validate, ship, measure, repeat. The depth scales with the tier, the structure does not.
Most CRO programmes start with assumptions. Ours start with evidence.
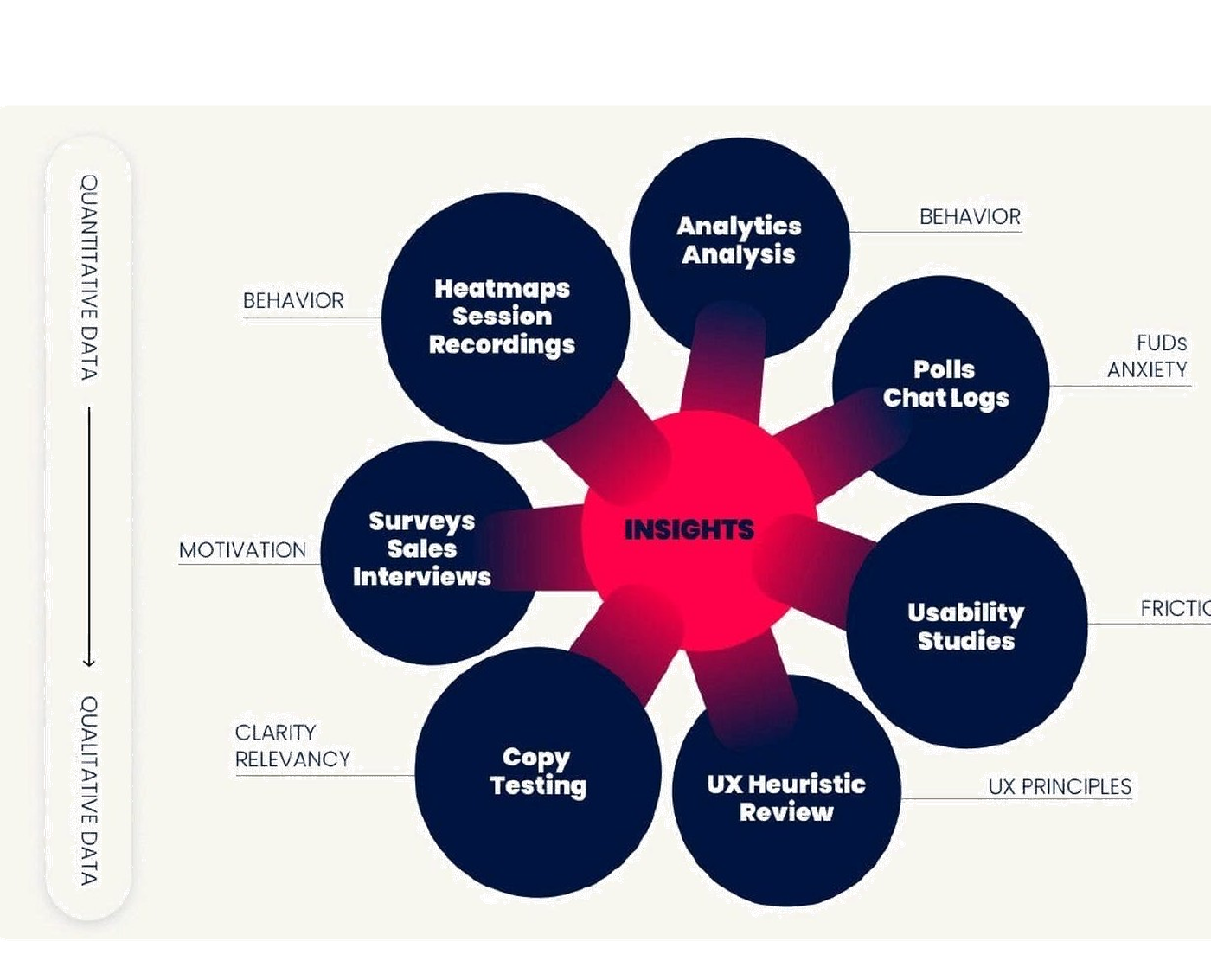
Before a single hypothesis enters the queue, we run a structured research pass across eight surfaces. Each one tells us something the others can’t.
Quantitative data tells us where users hit friction. Heatmaps, scroll maps, session recordings and analytics audits show patterns the funnel charts hide. Qualitative data tells us why. Surveys, sales interviews, polls and chat logs surface the language and the anxieties behind the clicks.
Each surface is mapped to a different conversion barrier. Behaviour. Friction. Anxiety. Motivation. Clarity. UX best practices. Together, they compound into insights, and insights compound into wins.
No experiment we ship is a guess. Every variant traces back to a specific signal in the research. That’s the difference between a programme that compounds and a programme that runs in circles.
The roadmap, step by step.
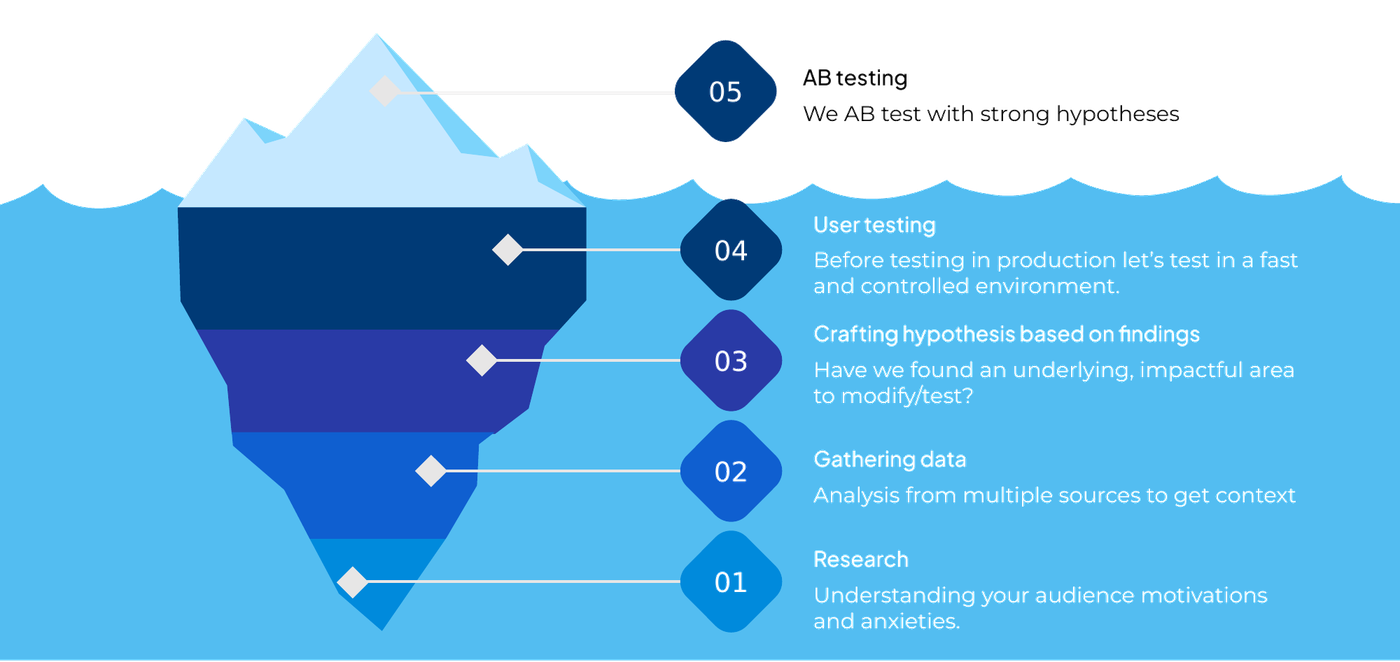
A linear flow per experiment, run in parallel as a programme. The visible part is the test. Most of the work happens below the surface.
Research
Start with the audience, not the site. Understand motivations and anxieties before touching a single pixel. The research pass on the previous section feeds directly into this step.
Gathering data
Combine quantitative and qualitative sources to get full context. GA4 funnels, heatmaps, recordings, polls and sentiment analysis. The goal is not to collect data, it is to find the leak everybody else missed.
Crafting the hypothesis
Have we found an underlying, impactful area to modify and test? A good hypothesis is specific, measurable, and tied to a business case. Each one is ranked via PXL prioritisation before it enters the testing queue.
User testing
Before we ship to production, we test the variation in a fast, controlled environment. Five-second tests, preference tests, qualitative interviews. Catches the obvious problems before they reach real traffic.
A/B testing
Run the live experiment with enough power to declare a winner with confidence. Pre-registered hypothesis, primary and guardrail metrics, MDE calculated upfront. Winners ship. Losers become learnings. The cycle restarts.
Each cycle sharpens the next.
A single A/B test is a coin flip. A programme of structured tests is a learning system that gets better month over month.
Every winning experiment teaches us about your audience. Every losing one too. The losses are often more valuable, because they kill an assumption nobody had questioned.
After three cycles, the hypothesis quality is sharper. After six, the test win-rate climbs. After twelve, the compounding lift on the same traffic is significant enough that paid-media efficiency goes up too. CRO is the only growth lever where last quarter’s wins keep paying this quarter.
That is what a research-led programme buys you. Not just more conversions next month. A more accurate map of how your customers actually decide, and a team that gets better at reading it.